全文検索エンジンFessでゲームの攻略サイトを検索する
業務でFessを使ってみたのでQiitaに記事を載せました。
ここにも載せておきます。
1.艦これWikiを検索したい
艦これwiki
http://wikiwiki.jp/kancolle/
のようなゲーム攻略サイト内の検索BOXを使ってみると。
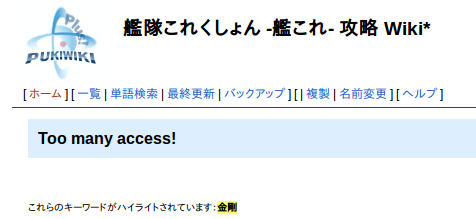
Too many access!
という感じで検索がうまくできないことがあります。これは不便です。何か良い方法はないものか・・・。
2.Fessを導入
ということでFessという全文検索サーバを使ってみました。公式サイトはこちらです。 http://fess.codelibs.org/ja/ Fessは全文検索サーバと言われるもので、指定したWebサイトやファイルシステムを検索してくれます。これで艦これwikiを検索できるようにします。
早速やってみます。環境を作るのは非常に簡単です。
1.公式のサイトからzipファイルを落としてきて展開。
2.fess\fess-server-?.?.?\bin\ の中にあるstartup.batを実行する。
3.http://localhost:8080/fess を開く
4.↓の画面が表示されれば成功

これで準備は整いました!簡単ですね。この時点でまだドキュメントを登録していないので、検索を行っても検索結果が0件になります。
3.Fessを使う
では早速管理ページでドキュメントを登録してみます。
http://localhost:8080/fess/admin
ここにアクセスするとユーザ名とパスワードを聞かれます。デフォルトでは共にadminを入力すれば入れます。

最初、設定ウィザードの画面が開いていますが、これは初めてFessを使う人が簡単にクロールの設定ができるように置いてあるものです。とりあえずこれは無視して「クロール」欄の「ウェブ」を開き、「新規作成」をします。
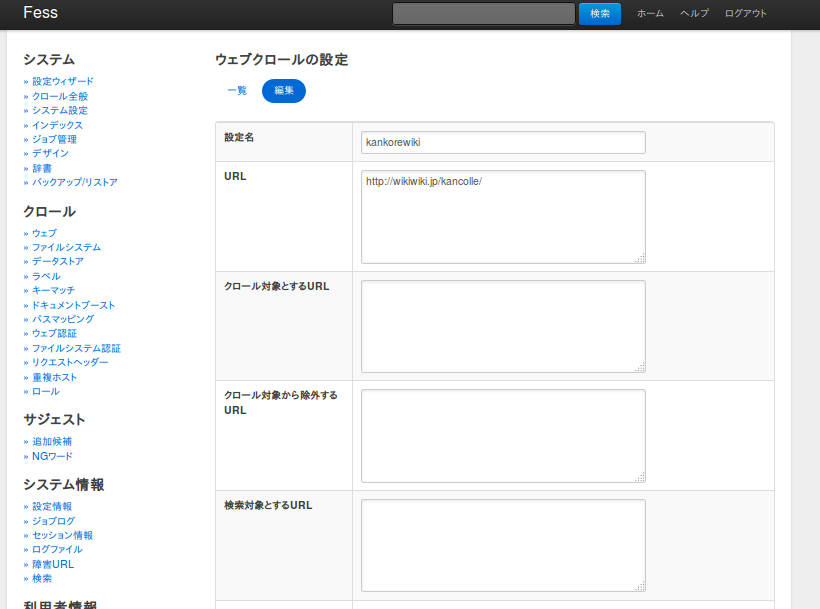
「設定名」は任意です。kankorewikiとしておきました。「URL」にクロールしたいURLを書きます。http://wikiwiki.jp/kancolle/ にします。「最大アクセス数」は10000、「間隔」は1000ミリ秒としておきます。他はデフォルトにします。「作成」をクリックして設定内容を確認して下の「作成」をクリックします。これでウェブクロールの設定が終わりました。
次に「システム」欄の「システム設定」を開きます。

クローラー状態欄の「クロールの開始」をクリックします。これでクローラが動きます。しばらく経つとクローラーの状態が実行中から停止中になります。クロールが完了するまで待ちます。
クローラーが停止したのを確認したら一度ログアウトします。
http://localhost:8080/fess/
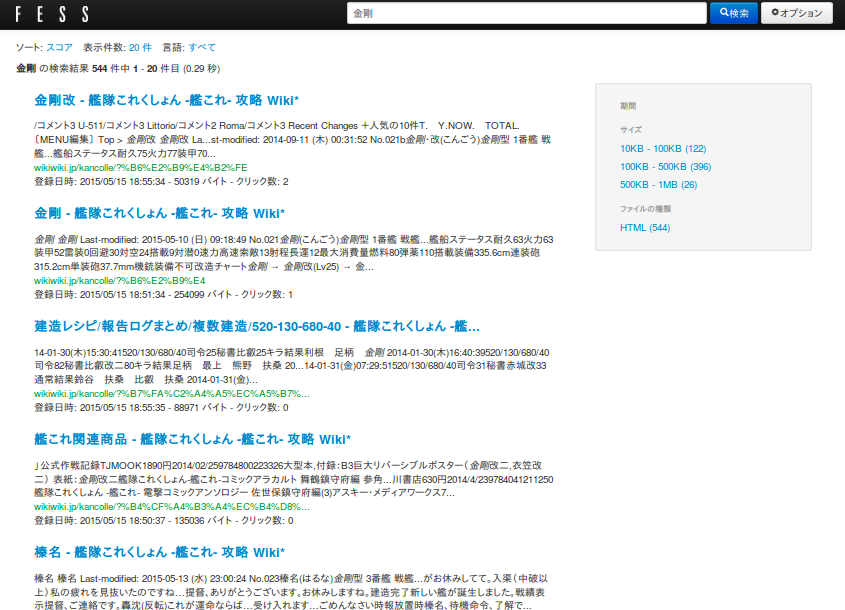
を開き検索BOXに「金剛」と入力。
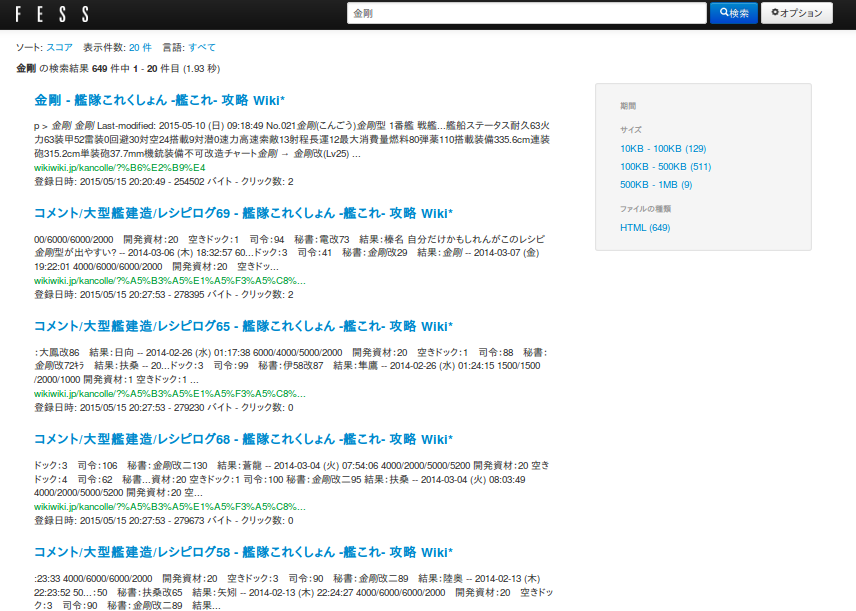
検索結果が出てきます。最上位に表示されているリンクを開くと見事に金剛のページにアクセスできます。

4.クロールの設定
これで目標達成、と言いたいところですが少し問題点がありました。それは先ほどの検索結果の画面で最上位以外のリンクが「コメント/大型艦建造/レシピログ??」となっていています。開いてみるとただのログで有益な情報が載っていません。このようなリンクは邪魔ですから表示したくありませんね。そこで「コメント/〜」をクロール対象外にすることにします。
「クロール」欄の「ウェブ」を開き、先ほど作成したkankorewikiを編集します。
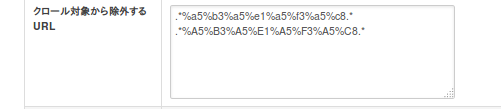
「クロールの対象から除外するURL」に以下を追加してください。
.*%a5%b3%a5%e1%a5%f3%a5%c8.*
.*%A5%B3%A5%E1%A5%F3%A5%C8.*
http://www.tagindex.com/tool/url.html
等のサイトでデコードすれば分かりますが、上記文字列は「コメント」を意味しています。これで「コメント/〜」はクロールされなくなります。
編集を完了し、再度クロールをする前に前回のクロールの情報を削除しておきます。「システム」欄の「インデックス」をクリックします。
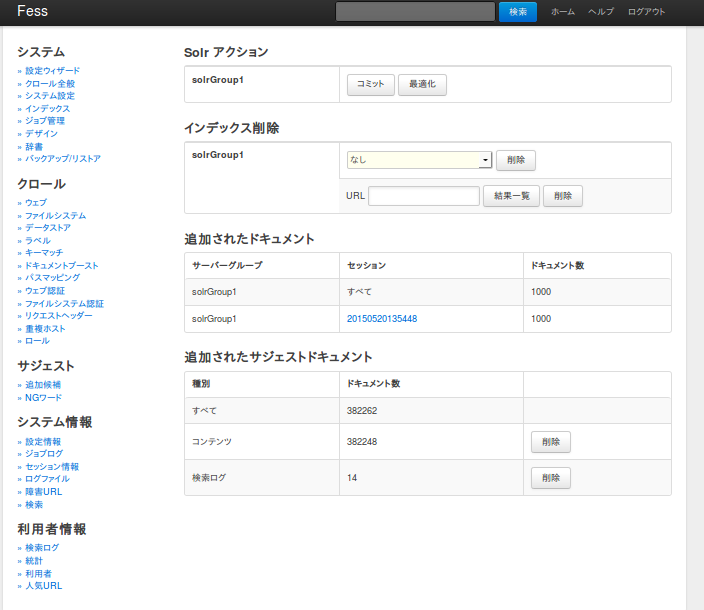 インデックス削除から「なし」を「すべて」に変えて削除をクリックします。これでインデックスが削除されました。
では前回と同じようにクロールを実行します。「システム設定」からクロールを開始します。
クロールが停止したのを確認してからログアウトし、検索BOXに「金剛」と入力。
インデックス削除から「なし」を「すべて」に変えて削除をクリックします。これでインデックスが削除されました。
では前回と同じようにクロールを実行します。「システム設定」からクロールを開始します。
クロールが停止したのを確認してからログアウトし、検索BOXに「金剛」と入力。
cUrlコマンドの使い方
cUrlとはHTTPアクセスをしてコンテンツを取得できるコマンドのことです。Elasticsearchを使う上で必要となるので、まとめておきます。
環境はLinuxで行いました。
ページ取得
基本的な使い方としては、URLをパラメータにしてそのコンテンツを標準出力させます。$ curl yahoo.co.jp
上のように入力すると、YahooのサイトのHTMLが表示されます。
-o ファイル名
取得結果をファイルに保存します。以下のように入力すると、URLのファイルがu.dataというファイル名で保存されます。
$ curl -o u.data http://files.grouplens.org/datasets/movielens/ml-100k/u.data
-X
使用する要求のコマンドです。HTTPリクエストと一緒に使われます。
HTTPリクエストメソッド
一部、http://research.nii.ac.jp/~ichiro/syspro98/http.htmlを参考にしてまとめていきます。Webサイトを見る時、サーバに対して「サイトを見たい!」という要求を出します。この要求のことをリクエストと言います。
HTTPリクエストメソッドには以下の種類があります。
- GET : 情報をWebプラウザに返す。
- POST: サーバに情報を送る。
- PUT : サーバに情報を送り、サーバ上で保存。
- DELETE : サーバの情報を削除。
- HEAD : ヘッダ情報を要求する。
- CONNECT : プロキシサーバを通す。
- OPTION : 通信オプションを調べる。
- TRACE : 要求がどのプロキシサーバを経由して送信されるかを返す。
- LINK : 指定した URL とリソースにリンク関係を結ぶ。
- UNLINK : LINKを解除する。
これ以降、Elasticsearchで試してみました。
-XPUT
データを入れる場合に使用します。インデックス名「twitter」、タイプ名「tweet」で作成します。
$ curl -XPUT 'http://localhost:9200/twitter/tweet/1' -d '{ "user" : "kimchy", "post_date" : "2009-11-15T14:12:12", "message" : "trying out Elasticsearch" }'
すると、以下のように表示され、データを挿入できます。
{
"_index" : "twitter",
"_type" : "tweet",
"_id" : "1",
"_version" : 1,
"created" : true
}
-XGET
データの情報を取得します。以下のように入力すると、userが"kimchy"であるデータの情報が返ってきます。
$ curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy'
-XPOST
以下のように入力すると、"index.mapping.allow_type_wrapper"が"true"であると設定することが出来ます。$ curl -XPOST 'http://localhost:9200/twitter' -d '{ "settings": { "index": { "mapping.allow_type_wrapper": true } } }'
-XDELETE
データを削除することが出来ます。下のように入力すると、Elastic Searchで全てのデータ(index)を削除します。
とても怖いコマンドなので、気をつけましょう!
$ curl -XDELETE 'http://localhost:9200/*'
下のように入力すると、"twitter"という名前のindexが削除されます。
$ curl -XDELETE 'http://localhost:9200/twitter/'
以下のいずれかを入力すると、userが"kimchy"であるデータを削除することが出来ます。
$ curl -XDELETE 'http://localhost:9200/twitter/tweet/_query?q=user:kimchy' $ curl -XDELETE 'http://localhost:9200/twitter/tweet/_query' -d '{ "query" : { "term" : { "user" : "kimchy" } } } '
-d
フォームの送信と同様のことを行うためのオプションです。- dの後に、「 name=value 」という形でフォームの名前と値をイコールでむすびます。これは下のように複数個つけることが可能です。
curl -d u_ID=userid -d PassW=password http://www.n2sm_intern.com/login.cgi
-I
HTTPヘッダを取得するために使用するオプションです。以下のように入力すると、ヘッダ情報が出力されます。
curl -I http://www.n2sm.net/
出力
HTTP/1.1 200 OK Date: Mon, 25 May 2015 07:14:29 GMT Server: Apache/2.2.29 X-Powered-By: PHP/5.2.17 P3P: CP="NOI NID ADMa OUR IND UNI COM NAV" Cache-Control: private, must-revalidate Set-Cookie: 19vyu7gicuf40sc4o40gcsgks=a2a105bf41afc90c669ee6ada6367d27; path=/ Set-Cookie: 19vyu7gicuf40sc4o40gcsgks=a2a105bf41afc90c669ee6ada6367d27; path=/ Content-Type: text/html; charset=UTF-8
-u
認証が必要となるサイトでは、ユーザIDとパスワードが必要となります。例えば、以下のようにユーザIDとパスワードをコロンでつなげて入力します。
$ curl -u userid:password http://www.n2sm_intern.com/member/
grepコマンドで作業効率UPを図る
grepとは文字列を検索するコマンドのことです。目的のファイルを探したりする上でgrepを使いこなす必要が出てきました。grepを使いこなすことで作業効率はぐんと上がるらしいのでこれを機に勉強してみました。
環境はLinuxで行いました。
テキストファイルの内容を検索する
ファイル中にある特定の文字列を探したい時があります。ここでは例としてホームディレクトリ直下に以下の内容のtest.txtを作ります。
abcdefghijklmnopqrstuvwxyz 0123456789 qawsedrftgyhujikolp;@ azsxdcfvgbhnjmk,l.;/:] 5line 6line 7line 8line 9line
ホームディレクトリ内で次のコマンドを打つと
grep abc test.txt
以下の結果が出力されます。
abcdefghijklmnopqrstuvwxyz
このコマンドの意味はtest.txtからabcの文字列を見つけてその行を出力するとなります。1行目にabcを含んだ文字列があったので、その行が出力されました。
次です。grepは複数のファイルから一気に文字列を検索できます。試しにtest2.txtとtest3.txtを作成。
test2.txt
zyxwvutsrqponmlkjihgfedcba 0123456789 qawsedrftgyhujikolp;@ azsxdcfvgbhnjmk,l.;/:]
test3.txt
abcdefghijklmnopqrstuvwxyz 9876543210 qawsedrftgyhujikolp;@ azsxdcfvgbhnjmk,l.;/:]
以下のコマンドを打つと
grep abc test*
次の結果が得られます。
test.txt:abcdefghijklmnopqrstuvwxyz test3.txt:abcdefghijklmnopqrstuvwxyz
複数のファイルの中身のabcを検索し、出力しています。「:(コロン)」の前はファイル名です。test*の「*」は任意の文字列を表しています。つまりtestやtest2、test3、testhogeなどのファイル名が検索対象となっています。ここで使われている「*」はワイルドカードと言って、他にも様々なワイルドカードが存在します。ワイルドカードについては http://itpro.nikkeibp.co.jp/article/COLUMN/20070514/270907/?ST=oss が詳しいです。
「|(パイプ)」を使ってコマンドの出力から検索する
パイプを使うことでコマンドの出力内容に対して検索をすることができます。次のコマンドを打ってみます。
ls | grep test
以下が出力されます。
test.txt test2.txt test3.txt
パイプは左側のコマンドの出力を右側のコマンド入力に渡します。つまりlsの出力であるファイル名やディレクトリ名をgrepの入力として渡し、その中からtestを含むファイル(ディレクトリ)名を検索しています。パイプを使えば色々なコマンドの合わせ技ができそうですね。
パイプの便利な合わせ技としてfindコマンドを使ったものがあります。findコマンドはファイルやディレクトリを検索するコマンドです。詳しい使い方やオプションは
http://itpro.nikkeibp.co.jp/article/COLUMN/20060227/230777/?ST=oss
を参照してください。
例えば次のコマンドを打ってみます。
find . -name "*.*" | xargs grep hoge
このコマンドの意味は"カレントディレクトリ"以下のサブディレクトリから "*.*"という形式の名前のファイルを探し、その出力をgrepのパラメータとして受け取り"hoge"と書かれてある行を探し出力するとなります。
(xargsの使い方は
http://itpro.nikkeibp.co.jp/article/COLUMN/20140331/547143/?ST=oss )
要はファイルをfindで探してからそのファイルの中身をgrepで検索するということです。ディレクトリの中を再帰的に探してくれるfindとgrepの合わせ技は強力ですね。
便利なオプション
grepコマンドのオプションについては http://itpro.nikkeibp.co.jp/article/COLUMN/20060227/230820/?ST=oss に詳しく記載があります。試しにAオプションとBオプションを使ってみました。以下のコマンドを入力。
grep -B 1 -A 2 7line test.txt
出力
6line 7line 8line 9line
検索した7lineの前1列、後ろ2列も余分に表示されています。Bの引数に指定した数だけ後ろの行が表示され、Aの引数に指定した数だけ前の行が表示されています。検索した文字列の近くの行に何が書かれてあるか知りたい時に便利ですね。
他にも色々・・・。
以上、grepコマンドの主な機能でした。これ以外に使い方はいくらでもありそうです。しっかり使いこなして日頃の作業効率を上げていきたいところですね。